Assignment: Data pre-processing for ML
DUE WEDNESDAY, OCTOBER 11 AT 5:00PM.
Table of contents
In this assignment, you will be exploring the effect of data preprocessing techniques on the performance of a downstream machine learning model.
Overview
You will be working with two dirty tabular datasets:
- run-or-walk: Data from wrist devices that have acceleration and gyro information. The target column is 0 or 1 to denote walking/running.
- obesity: Data depicting obesity levels based on eating habits and physical conditions of individuals. The target column “NObesity” allows classification in 7 groups.
Your goal is to develop appropriate data preprocessing pipelines for each dataset to enhance the test accuracy of a Logistic Regression model (sample training code). The trained model will be used to predict the target variable for each of the datasets as a classification task. The model’s performance will be evaluated using a hold-out test set, which you will not have access to.
You can also find all assignment related files on canvas, under the Files > Assignment folder.
Specific Requirements
To ensure that the focus of your efforts is on data pre-processing, we will make the following simplifications:
- We expect that the pre-processed dataset will contain a subset of the columns from the original dataset. In other words, you can perform feature selection to drop irrelevant columns from the data, but you can not perform feature extraction to create new columns.
- Please do not apply any feature encoding on the pre-processed dataset. During the evaluation, we will apply one-hot encoding on all categorical features.
- Please do not use deletion as a data repair strategy to ensure no test examples are removed.
Pre-processing steps to consider
Here are some common data errors that you might want to consider addressing in the dataset:
- Missing values (categorical and numerical columns)
- Numeric outlier values
- Inconsistencies and duplicated data
You may utilize existing Python libraries (e.g., sklearn.preprocessing, sklearn.impute) or design your own detection and repair methodologies.
Besides handling the above errors, consider the following transformations:
- Scaling and Normalization
- Discretization
- Feature selection
Feel free to use different preprocessing techniques for different data columns.
Part 1: Code Submission
There are 2 assignments set up on Gradescope:
Submission files:
- Python Script (pre-process.py): Contains a function
preprocess_data()that performs pre-processing on the respective dataset. - Requirements (
requirements.txt): Lists Python packages required to run your script.
The template for these files can be found on Canvas. Do not include print statements or alter file/function names in the template files; the autograde will break otherwise.
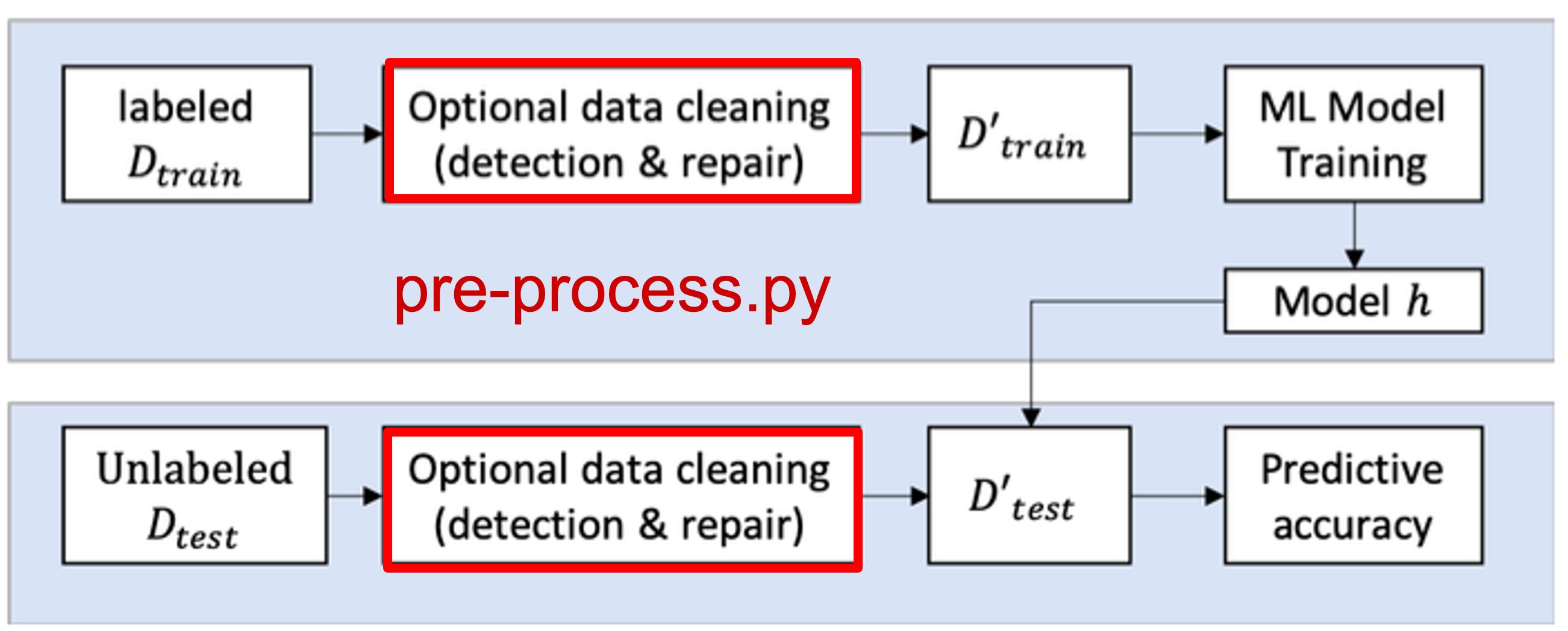
Your pre-processing pipeline will be applied to both training and test data for the relevant dataset. A logistic regression model will then be trained on the pre-processed training data, and accuracy on the test data will be reported. Please note that you are allowed a maximum of 15 submissions per dataset to avoid overfitting to the test dataset.
Part 2: Report Submission
Submit a PDF that describes your overall approach on canvas. The report should not exceed 1.5 pages (single-spaced, 12pt font size). Your report should contain the following information:
- Describe the data preprocessing operators and algorithms you explored, including both existing libraries and custom algorithms
- Explain your methodology for selecting the best-performing pre-processing pipeline for each dataset. Include references to any research papers used.
- Discuss your best-performing preprocessing pipelines for both datasets.
Grading
The grading breakdown of this assignment is as follows:
- Obesity dataset (15pts):
- Code (5pts): Automatically awarded for a valid entry on the leaderboard.
- Accuracy (10pts): Is test accuracy > 94%.
- Run-or-walk dataset (15pts):
- Code (5pts): Automatically awarded for a valid entry on the leaderboard.
- Accuracy (10pts): Is test accuracy > 84%?
- Report (10pts):
- Completeness (6pts): Does the report contain all required information (design space, search strategy, and final result)?
- Clarity (4pts): Is the writing overall clear and easy to follow for a technical expert in the field?
- Extra credit (4pts): We will combine your ranks on the two leaderboards. The top 3 lowest combined ranks will each receive +4 points as extra credit.
Collaboration Policy
This is an individual assignment so we expect one submission from each student. You are encouraged to work with other students to discuss ideas and strategies. However, we expect you to perform the implementation on your own. Direct sharing of preprocessing pipelines with configurations and parameters is prohibited.